Most SEO teams waste months creating pages that compete with each other without realising it. Keyword clustering solves this by turning scattered keyword lists into structured content strategies.
This guide covers what keyword clustering is, why it matters for SEO rankings, and how to build a full clustering workflow from scratch, from a raw keyword list to a mapped content structure.
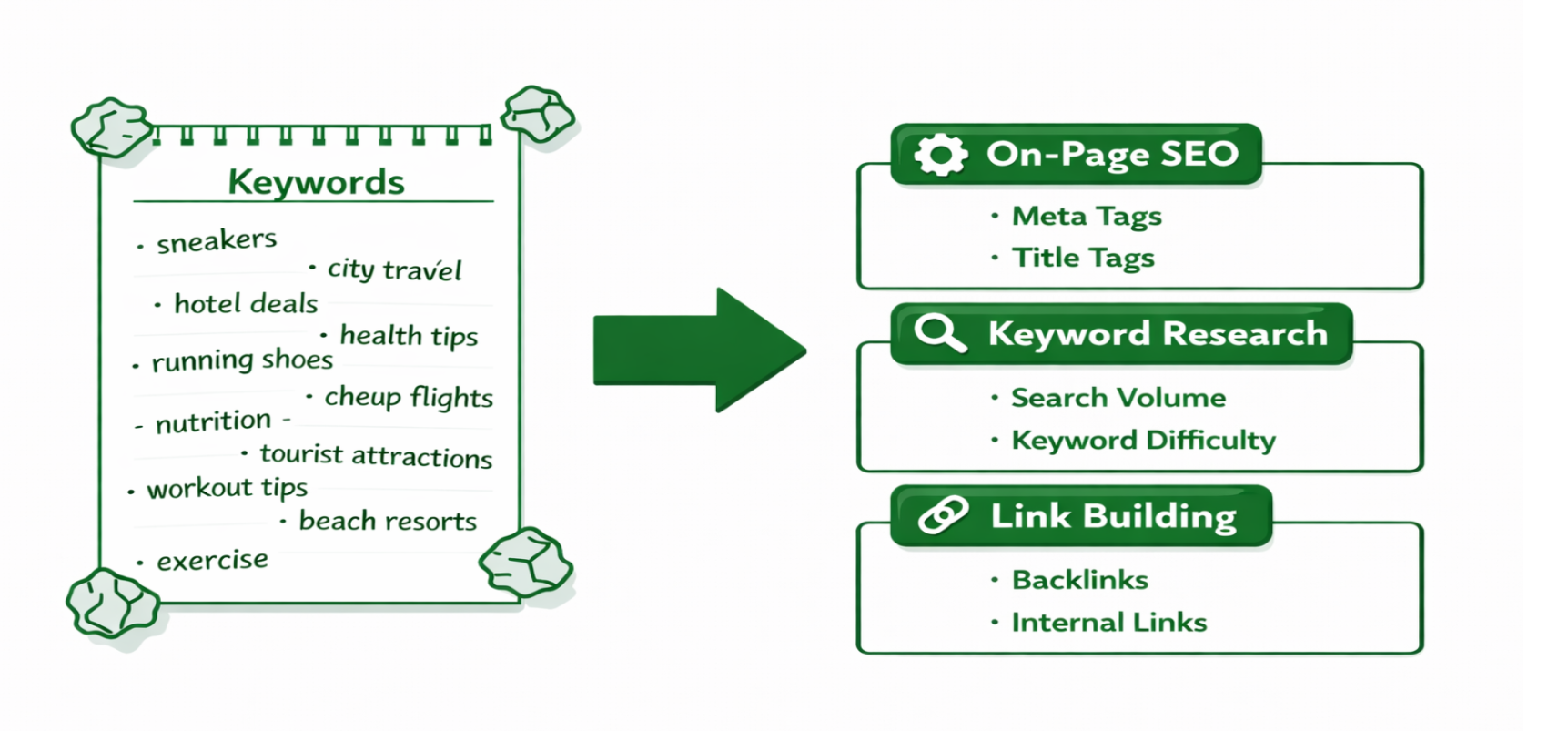
What is keyword clustering
Keyword clustering is the practice of organizing keywords into groups based on shared topic and search intent. Each cluster maps to one primary page. Supporting keywords within that cluster inform the sections, FAQs, and subpages of that one URL rather than spawning separate competing pages.
The underlying principle is simple: one topic, one page, covered well. When a page is built around a full cluster instead of a single keyword, a single well-optimized page can rank for over 2,200 keywords and drive 183,000+ organic visits per month. That kind of reach is impossible when you are targeting one keyword per page.
Clustering connects directly to the pillar-cluster model, where a broad pillar page covers a main topic and supporting cluster pages go deep on subtopics. This architecture sits at the core of how on-page SEO is structured for sites that want to build sustained ranking authority rather than chase individual keywords.
Why keyword clustering matters for SEO
Clustering is not just an organizational habit. It directly affects how search engines understand and rank your content across three key areas.
It prevents keyword cannibalization
Keyword cannibalization happens when multiple pages on your site target the same or similar keywords. Google gets confused about which page to surface, rankings become unstable, and authority gets split across URLs. Clustering assigns clear ownership: one topic belongs to one page, and nothing else competes with it.
It builds topical authority
Search engines reward sites that cover topics in depth, not just breadth. When your pages are organized into tight clusters with strong internal linking, Google can see that your site owns a subject area. Structuring content into topic clusters around a pillar page makes it easier for search engines to index related subtopics and directly improves how many queries your content surfaces for.
It improves internal linking quality
Random internal links are mostly useless. Clustering gives you intentional paths. Pillar pages link out to cluster pages, cluster pages link back with descriptive anchors, and related clusters cross-link where relevant. The result is a crawl-friendly structure that distributes internal link equity efficiently and signals clear hierarchy to search engines.
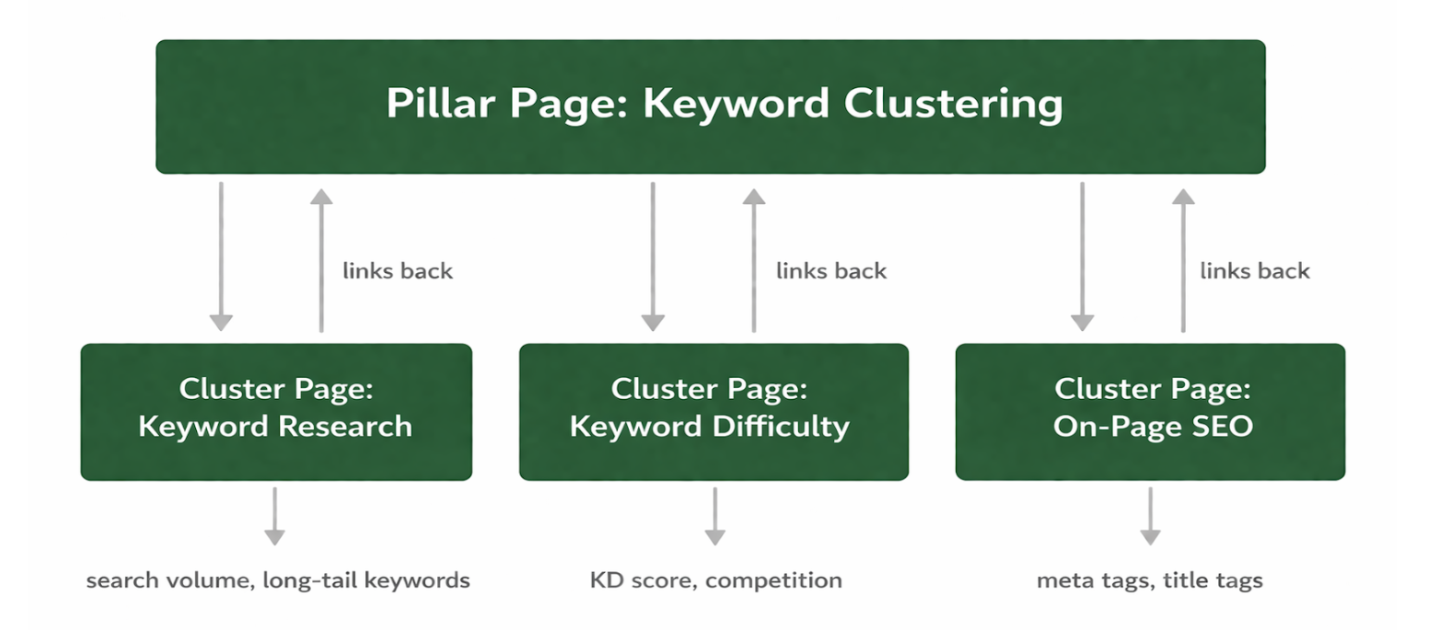
The two main types of keyword clustering
Before you start grouping, it helps to know the two approaches most tools and teams use.
Clustering type | How it works | Best for |
SERP-based clustering | Group keywords that rank for the same URLs in Google. Reflects actual search engine behaviour. | Most SEO teams. Most accurate for intent alignment. |
Semantic clustering | Group keywords by meaning using NLP or embedding models. Catches synonyms even when SERPs differ. | Large keyword sets. Useful when SERP data is limited. |
Many teams combine both. Run SERP-based clustering first, then use semantic methods to catch related phrases that the SERP approach missed.
How to do keyword clustering in five steps
Here is a practical workflow you can follow with any size keyword list.
Step 1: Build your keyword list
Start broad. Pull keywords from multiple sources: your SEO tool of choice, Google Search Console, competitor research, and autocomplete suggestions. Include seed terms and long-tail variations. The full process of keyword research, from finding seed terms to analyzing search volume, should happen before you start clustering. At this stage, quantity matters more than precision.
Step 2: Clean and normalize the data
Remove duplicates, fix inconsistent formatting, and strip irrelevant terms. Keywords that look similar may serve completely different intents once you look closely. Cleaning now saves confusion later.
Step 3: Assess search intent for each keyword
Intent is the most important clustering signal. Before grouping anything, sort your keywords by the type of answer they need:
Informational - the user wants to learn (e.g. what is keyword clustering)
Navigational - the user wants to find a specific site or page
Commercial - the user is researching before a purchase (e.g. best keyword clustering tools)
Transactional - the user is ready to act (e.g. buy keyword research software)
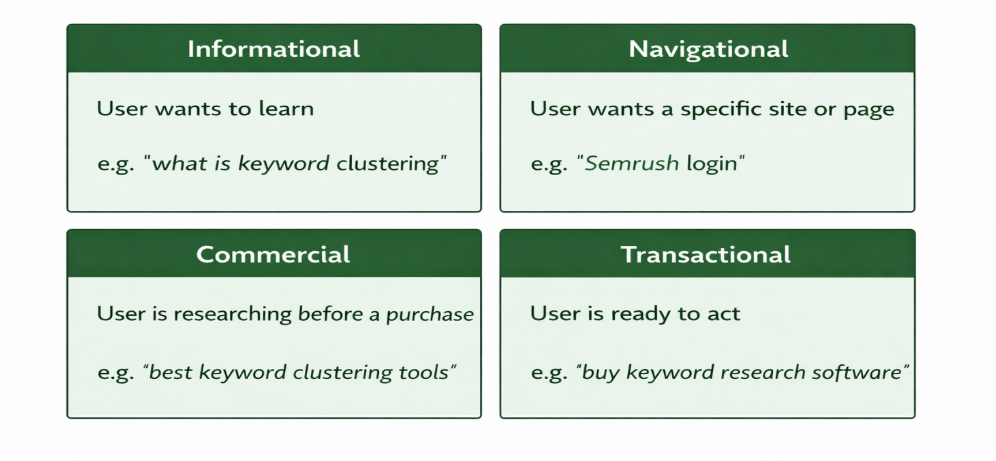
Keywords with different intents rarely belong in the same cluster, even if they look similar on the surface.
Step 4: Group keywords into clusters
With intent sorted, group keywords that share the same topic and would be satisfied by the same page. Apply a clustering method based on your dataset size:
Manual grouping - works well for lists under 200 keywords. Gives you full control.
TF-IDF with K-Means - a reliable baseline for medium lists (200 to 2,000 keywords). Groups by shared terms.
Embedding-based clustering - uses semantic similarity for large lists. Groups by meaning, not just wording.
The rule of thumb: one search intent equals one cluster equals one page. If a group of keywords would be better served by two different pages, split the cluster.
Step 5: Map clusters to content
Each cluster needs a destination. Decide whether it becomes a pillar page or a supporting page. Define the primary keyword, the supporting keywords, the target audience, and the content format the intent calls for. Document this as a brief before writing begins.
Clustering methods compared
Each method has real tradeoffs. Here is how they stack up for practical SEO work.
Method | Speed | Accuracy | Scales well | Best use case |
Manual | Slow | High (with expertise) | No | Small lists, nuanced niches |
TF-IDF + K-Means | Fast | Medium-High | Yes | Standard SEO projects |
Embedding-based (semantic) | Medium | High | Yes | Large lists, synonym-heavy topics |
SERP similarity | Fast | Very high | Yes | When ranking, alignment matters most |
Most SEO teams do not need to choose one method permanently. SERP-based clustering combined with manual review handles most projects well. Understanding keyword difficulty for the terms in each cluster also helps you prioritize which clusters to build out first versus which ones need more authority before you target them.
From clusters to content architecture
Clustering is not the end of the process. It is the input for your content structure.
Each cluster maps to a pillar page that introduces the topic comprehensively. Supporting cluster pages explore subtopics in depth and link back to the pillar. This creates the architecture that search engines interpret as topical authority.
Content format should follow intent, not habit. Some clusters call for how-to guides. Others are better served by comparison pages, tool roundups, or FAQ content. The cluster determines the format.
Internal linking within the architecture matters enormously. Pillar pages link outward to cluster pages with descriptive anchor text. Cluster pages link back to the pillar. Where two topic clusters genuinely overlap, cross-linking reinforces the connection without creating confusion. This is why site architecture built around clusters tends to outperform sites where pages are published without a structural plan.
How to measure keyword cluster performance
Tracking individual keyword rankings is useful but incomplete. To understand whether your clustering is working, you need to measure at the cluster level. Using keyword clustering as the core of a content strategy helped one site grow organic traffic from 2,000 to over 15,000 visits per month a result driven largely by cluster-level tracking rather than keyword-by-keyword monitoring.
Track these metrics for each cluster over time:
Total organic traffic to all pages in the cluster
Number of keywords each cluster page ranks for in positions 1 to 20
Click-through rate (CTR) by page, to catch ranking pages that are not getting clicks
Crawl coverage — are all cluster pages being indexed and crawled regularly?
Re-clustering is also part of the process. Quarterly or semi-annual reviews are enough for most niches. New keywords emerge, intent shifts, and competitors create new content. Your clusters should reflect the current landscape, not the one from eighteen months ago.
Common keyword clustering mistakes to avoid
Even experienced SEO teams make the same clustering errors. Here are the ones that cause the most damage.
Grouping by topic instead of intent
Two keywords can share a topic but demand completely different content. "Keyword clustering tools" (commercial intent, wants a list) and "how keyword clustering works" (informational intent, wants an explanation) should not live on the same page. Always sort by intent before you group by topic.
Making clusters too small
Over-clustering into dozens of tiny groups creates a fragmented site with thin content everywhere. If a cluster has fewer than three to four supporting keywords, consider whether it is a genuine standalone topic or a subtopic that belongs in a larger cluster.
Ignoring keyword cannibalization that already exists
Clustering new content without auditing what already exists on your site is a common mistake. Before you plan new pages, check whether you already have pages competing for the same clusters. Merging, redirecting, or consolidating existing pages often delivers faster results than creating new ones.
Skipping the measurement step
Clusters that are never tracked are never improved. Setting up basic cluster-level reporting in Google Search Console or your rank tracker takes an hour and pays dividends for years.
Keyword clustering best practices
Good clustering is not just about grouping keywords correctly. It is about building a system that holds up over time, scales as your site grows, and keeps search engines and users aligned on what every page is about. These practices separate sites that rank consistently from ones that cluster once and wonder why nothing moved.
One cluster, one page, no exceptions: Every cluster must map to exactly one page. The moment you find yourself thinking "this could go on either page" that is a signal to either split the cluster or redefine the page scope. Shared ownership between two pages means neither page wins. Example: "keyword clustering" and "keyword clustering tools" share a topic but not an intent. Two clusters, two pages.
Always sort by intent before you sort by topic: Topic similarity is not enough to justify grouping. Two keywords about the same subject can need completely different pages if the intent behind them differs. Run every keyword through an intent check first informational, navigational, commercial, or transactional before you assign it to a cluster. Example: "what is keyword difficulty" (informational) and "keyword difficulty checker" (commercial) both relate to keyword difficulty but belong on separate pages.
Validate every cluster against live SERPs: Before you finalize a cluster, Google the primary keyword and study the top 10 results. The SERP tells you what format, depth, and angle Google currently rewards for that query. If every top result is a step-by-step guide, your page should be a step-by-step guide. If they are all tool comparisons, match that format. Example: Google "keyword clustering tools" if all top results are listicles with 10+ tools, a definition page will not rank no matter how well it is written.
Set a minimum cluster size before creating a page: A cluster with two keywords is usually a subtopic, not a standalone page. Before you create a new URL, make sure the cluster has enough keyword volume and supporting terms to justify a full page. A good minimum is 5 to 8 supporting keywords around one clear primary keyword. Example: "keyword clustering for ecommerce" with only 2 keywords is better handled as a section inside your main keyword clustering guide, not a separate page.
Clean your keyword list before you start grouping: Near-duplicate keywords inflate your list and create false clusters. Before clustering, remove duplicates, standardize spelling variations, and strip keywords that do not match any real topic on your site. Garbage in means garbage clusters out. Example: "keyword clustering", "keywords clustering", and "clustering keywords" are the same thing. Keep the highest volume version and remove the rest.
Name every cluster before you write: The cluster name becomes your H1, your URL, and your content brief. Vague cluster names produce vague pages. Be specific enough that anyone on your team could pick up the brief and know exactly what the page covers and what it does not cover. Example: "SEO content" is too vague. "How to do keyword clustering for an SEO content strategy" is specific, scoped, and maps directly to a URL.
Review and update clusters every quarter: Search intent evolves. New tools launch. Competitors create content that shifts what Google rewards. A cluster you built 12 months ago may need new supporting keywords, a different format, or splitting into two pages entirely. Quarterly reviews keep your architecture aligned with how people actually search today. Example: A cluster around "AI SEO" from early 2024 would look completely different now subtopics like LLM visibility, AI Overviews, and generative engine optimization have all emerged as standalone clusters since then.
Map every cluster to a URL before writing begins Decide the destination page before a single word is written. This forces you to think about how the page fits into your site structure, which internal links point to it, and what anchor text makes sense. Pages written without a URL decision often end up as orphans with no internal link equity flowing to them. Example: Decide /guides/keyword-clustering owns this cluster. Now your internal links from related pages, your anchor text choices, and your content scope all align from day one.
Keyword clustering and AI search visibility
AI-powered search engines like ChatGPT Search, Perplexity, and Google's AI Overviews evaluate content differently from traditional search. They do not just match keywords to pages they look for brands and websites that clearly own a topic, cover it comprehensively, and have content that connects logically across multiple pages.
This is where keyword clustering becomes even more critical in 2026. When your content is organized into tight clusters with clear pillar pages and supporting pages, AI models can understand what your site is about, which topics you cover with authority, and which pages to cite when answering a user's question. A scattered site with no clustering gives AI models nothing to work with. A clustered site gives them a clear map.
URLs that include words related to a keyword have a 45% higher click-through rate which means well-clustered, clearly named pages have a structural advantage before content quality is even considered.
Use a tool
Once your clusters are built and your content is live, the next step is understanding how all your topics connect at an entity level which is exactly how AI models like ChatGPT and Perplexity interpret and cite brands.
Serplock's Topic Graph maps your content topics as entities, shows the relationships between them, and reveals which parts of your topic universe are missing or underdeveloped. It is the bridge between a keyword clustering strategy and full AI search visibility taking you from "I have clustered my keywords" to "AI models understand and cite my brand."
Just add your brand to Serplock, go to Topic Graph, and you will see your full entity map every topic you own, every connection between them, and every gap that is costing you citations in AI-generated answers.
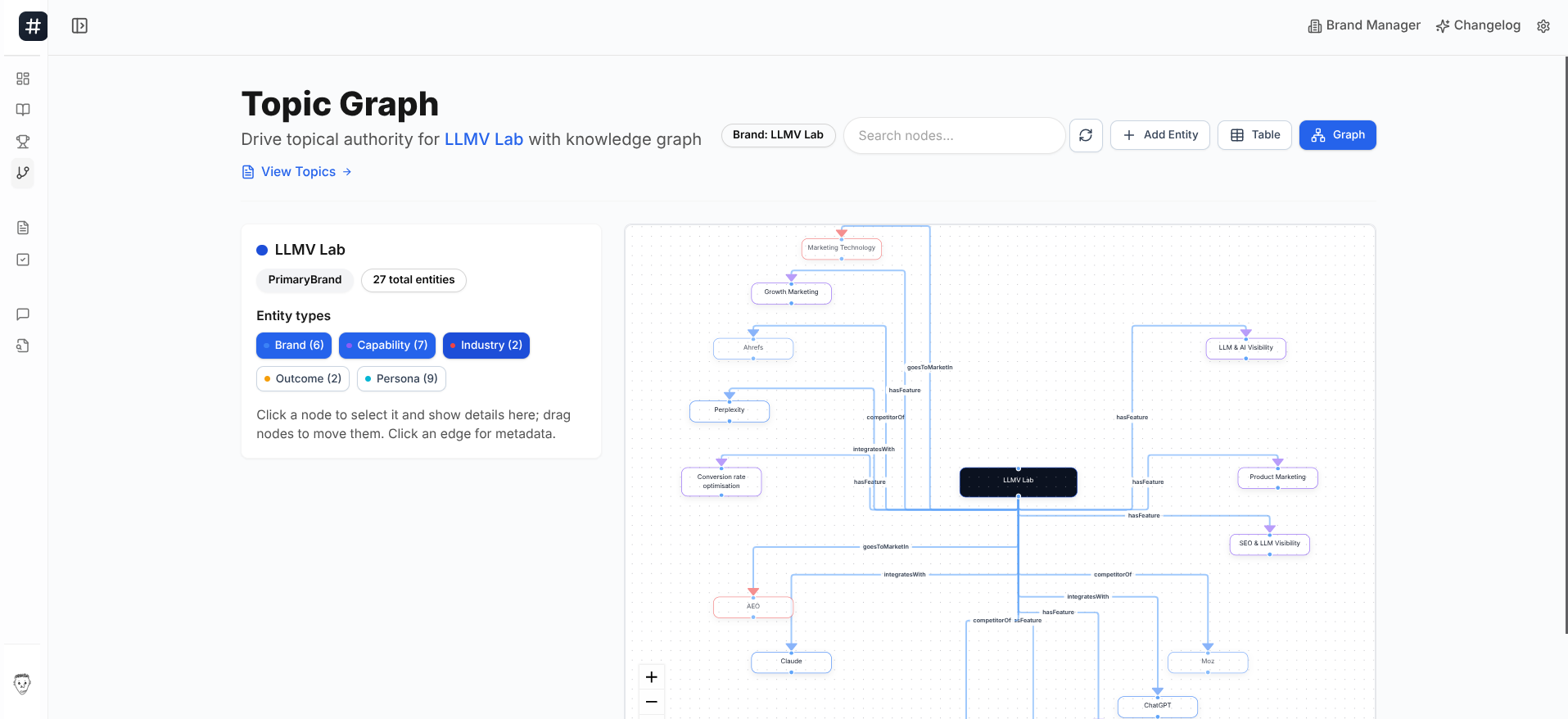
The sites that get cited in AI answers are not just the ones with the most content they are the ones where every topic connects to a clear brand narrative. Clustering gets you there at the keyword level. Topic Graph gets you there at the entity level.
Final thoughts
Keyword clustering is one of the highest-leverage activities in SEO planning. It takes a messy keyword list and turns it into a clear content architecture: every page has a defined topic, a clear audience, and no internal competition eating into its rankings.
The process is straightforward once you make intent the primary sorting signal. Group by what the user needs, not just what the words look like. Map each cluster to one clear page. Build internal links that reinforce the hierarchy. Track performance at the cluster level and refine over time.
Done consistently, clustering transforms SEO from a page-by-page guessing game into a system that compounds as your site grows.



