What is LLMs.txt and should you use it? [2026]
Every few months, a new file format or meta tag emerges that promises to dramatically improve your AI search visibility. Some of them matter. llms.txt has generated significant buzz since it was proposed in September 2024, with comparisons to robots.txt and claims that it could become the foundational AI crawling standard. Before you spend time implementing it, you deserve an honest answer about what the current evidence actually shows.
This does not mean llms.txt is worthless. It means you need to understand what it is, what the data says, and make a clear-eyed decision about whether the implementation effort is justified for your site right now. This guide covers all of that.
What llms.txt is
llms.txt is a proposed plain-text file placed at the root directory of a website — at yourdomain.com/llms.txt — that is intended to communicate to large language models which pages on your site contain the most important content. It was proposed by Jeremy Howard, co-founder of fast.ai, in September 2024 as a way to help LLMs navigate websites more efficiently given their limited context windows.
The idea builds on familiar web standards. robots.txt controls crawler access — it tells bots what they may not fetch. An XML sitemap supports discovery — it lists all important URLs for search engine indexing. llms.txt is different from both: it is about curation. Rather than controlling access or enabling discovery, it is designed to give AI systems a curated roadmap to your most important content, presented in a human-readable Markdown format that LLMs can process more efficiently than crawling complex HTML pages.
The file typically contains a brief description of your organization, links to your most important pages, and optional links to full Markdown versions of those pages for AI systems to read directly. It is written in Markdown, lives at your root domain, and is entirely public — anyone can view it by navigating to yourdomain.com/llms.txt.
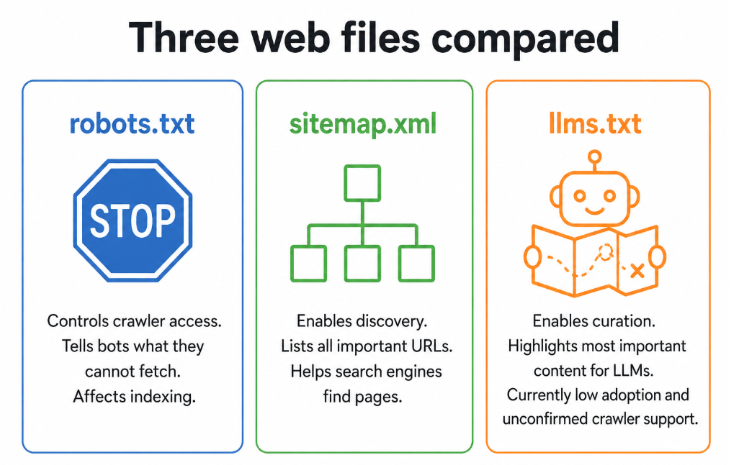
How llms.txt works in practice
An llms.txt file follows a simple Markdown structure. The root file at yourdomain.com/llms.txt contains your organization description and links to key pages. A companion file at yourdomain.com/llms-full.txt can optionally include the full Markdown content of all those pages concatenated together for AI systems that need everything in one document.
# LLM Visibility Lab
> Your comprehensive guide to AI SEO and LLM visibility optimization.
## Core guides
- [What is LLM visibility](https://www.llmvlab.com/guides/what-is-llm-visibility): The complete guide to brand presence in AI search
- [AI SEO](https://www.llmvlab.com/guides/ai-seo): How to optimize for AI-generated search results
- [GEO - Generative Engine Optimization](https://www.llmvlab.com/guides/generative-engine-optimization): The full GEO framework
## Tools and resources
- [Prompt tracking](https://www.llmvlab.com/guides/prompt-tracking): How to monitor your brand across AI platforms
- [LLM visibility strategies](https://www.llmvlab.com/guides/llm-visibility-strategies): Advanced strategy for enterprise LLM visibility
The structure is intentionally simple. The goal is to give an AI system reading your llms.txt file a clear, curated picture of what your site is about and what its most valuable pages cover — without requiring the AI to crawl and parse your entire site to form that picture.
The difference between llms.txt and robots.txt
This is the most common point of confusion. llms.txt and robots.txt are not the same type of file and they do not serve the same function.
| Dimension | robots.txt | llms.txt |
|---|---|---|
| Purpose | Controls what bots are allowed to crawl and index | Curates which content is most important for LLMs to process |
| Mechanism | Bots check robots.txt before crawling and follow its allow/disallow rules | LLMs optionally read llms.txt to understand content hierarchy — if they choose to |
| Crawler compliance | Nearly universally respected by all major search engine crawlers | Not yet adopted by any major AI platform as a required check |
| Impact if missing | Crawlers proceed without restrictions — may crawl everything | No impact — LLMs proceed with standard crawling if they support it at all |
| SEO maturity | Mature, universally adopted standard since 1994 | Proposed standard since 2024. Minimal adoption. No confirmed crawler compliance. |
The most important distinction is compliance. Robots.txt is respected because search engines and their business models depend on being good citizens of the web. llms.txt has no equivalent enforcement mechanism and no major AI platform has publicly committed to reading it as part of their standard crawl process.
What the data actually shows about llms.txt effectiveness
The most reliable evidence available on llms.txt effectiveness comes from three sources, and they converge on a consistent conclusion.
SE Ranking's 300,000 domain analysis
SE Ranking analyzed nearly 300,000 domains in late 2025. Only 10.13% of domains had an llms.txt file in place. Among those that did, having the file made no measurable difference to AI citation frequency compared to equivalent domains without one. Their conclusion: llms.txt does not currently impact how AI systems see or cite your content, but adding the file is a low-effort way to prepare for potential future adoption.
Search Engine Land's live server log experiment
Search Engine Land implemented llms.txt on their site in March 2025 and monitored server logs through October 2025. During that period, none of the major AI crawlers — Google-Extended, GPTBot, PerplexityBot, or ClaudeBot — accessed the llms.txt file. Only traditional crawlers like Googlebot and Bingbot visited it, and only for a handful of requests with no special treatment. Their LLM traffic grew over the same period, but attributed that to other optimization factors, not the file.
John Mueller and official platform positions
Google's John Mueller stated explicitly: "AFAIK none of the AI services have said they're using LLMs.TXT and you can tell when you look at your server logs that they don't even check for it." Google separately confirmed that its AI Overviews and AI Mode continue to rely on traditional SEO signals rather than llms.txt. OpenAI's crawler documentation makes no mention of llms.txt, though Anthropic did list the file in their documentation in late 2024. 8 out of 9 sites saw no measurable change in traffic after llms.txt implementation, according to Search Engine Land's broader survey.
The case for still implementing it
Given the current evidence, the case for implementing llms.txt is not about immediate impact. It is about three other considerations:
Future-proofing at low cost
The implementation effort for a basic llms.txt file is genuinely minimal — typically thirty minutes to one hour for a developer to create and deploy the file. The potential upside is that if and when major AI platforms begin actively reading the file, sites that already have a well-structured llms.txt in place may benefit from faster inclusion in AI citation systems than those that need to build it from scratch at that point. Early schema markup adopters in 2011 gained meaningful advantages when Google began using it for rich results. llms.txt may follow the same trajectory.
Content curation as a clarity exercise
Even if no AI crawler ever reads your llms.txt file, the exercise of writing one forces you to identify and articulate the most important pages on your site. This curation exercise has value independent of crawler compliance: it clarifies your content hierarchy for your own team, surfaces gaps in your coverage, and produces a document that could be used in other AI visibility contexts such as pasting into an AI prompt to give it context about your site.
Anthropic's documented acknowledgment
Anthropic listed llms.txt and llms-full.txt in their official documentation in November 2024. This does not confirm that Claude reads the file during standard crawls, but it does signal openness to the standard from one major AI platform. If Anthropic moves toward active llms.txt support, sites with well-structured files in place would benefit immediately.
The case against prioritizing it now
The more compelling case, based on current evidence, is that llms.txt should not be a priority for most sites when compared to the optimization activities that demonstrably improve AI visibility today.
The activities with confirmed, measurable impact on AI citation rates are: configuring robots.txt correctly so AI retrieval bots can access your content (see the robots.txt guide), implementing comprehensive schema markup that labels your content explicitly for AI systems (see the structured data for LLMs guide), building off-site brand mentions and entity authority (see the LLM visibility strategies guide), and maintaining content freshness so AI platforms with recency bias favor your pages over stale competitors. Every hour spent on these activities produces a measurably higher return than implementing llms.txt in the current environment.
How to implement llms.txt if you decide to
If your site is low-effort to implement on (static site, simple CMS, or a developer available to deploy a file), here is a clean implementation process:
- Step 1: Create a file named llms.txt in the root directory of your site.
- Step 2: Open with your organization name as an H1 heading, followed by a brief description in a blockquote.
- Step 3: Add sections for your most important content categories. Each section should be an H2 heading followed by bullet-point links with brief descriptions.
- Step 4: Include your core product pages, your most important guides, your documentation if you have a developer or SaaS product, and any resources that best represent your brand's expertise.
- Step 5: Optionally create an llms-full.txt file containing the full Markdown text of those pages concatenated for AI systems that want complete content in one request.
- Step 6: Reference the file in your robots.txt with an optional comment line for discoverability.
- Step 7: Verify the file is accessible by navigating directly to yourdomain.com/llms.txt in a browser.
Should you use llms.txt? The verdict
| Your situation | Recommendation |
|---|---|
| Low-effort implementation (static site, easy CMS) | Implement it — minimal cost, possible future upside, useful curation exercise |
| High-effort implementation (complex CMS, significant dev work) | Deprioritize — the evidence does not justify the cost. Focus on robots.txt, schema, and content quality first. |
| Developer tool, SaaS, or documentation-heavy site | Implement it — AI systems are more likely to reference documentation, and Anthropic's acknowledgment makes this higher value for dev-focused sites |
| Content site or blog without technical resources | Skip for now — implement robots.txt correctly and focus on schema markup and content freshness instead |
| Enterprise with a dedicated AI visibility program | Include it as part of a comprehensive technical AI visibility setup, alongside all other confirmed-impact tactics |
Conclusion
llms.txt is an interesting proposal that has not yet crossed the threshold from promising idea to confirmed standard. The current data is clear: AI crawlers are not reading it, it has no measurable impact on citation frequency today, and Google has explicitly stated they do not use it. That is the honest position as of mid-2026.
The right frame is this: it is the cheapest forward-looking bet available in AI visibility strategy. If implementation is genuinely low-effort for your site, there is no reason not to do it. If it requires significant development work, invest those resources in tactics with confirmed returns first — robots.txt configuration, schema markup, content freshness, and off-site entity building. Come back to llms.txt when the major AI platforms announce active support.
![What is Conversion Rate Optimization in AI search [2026]](https://cdn.sanity.io/images/cjp3nw01/production/cd66159971e24090347c156ab261051389e40d8a-1200x628.png)

